
工程师说 | 面向AD/ADAS的SoC的AI性能优化
摘要
本文介绍了瑞萨在早期设计阶段针对自动驾驶(AD)和高级驾驶辅助系统(ADAS)的SoC中用于AI处理的深度神经网络(DNN)加速器的性能、电路尺寸和功耗的工作内容。
Yuji Obayashi
Principal Software Engineer
背景
近年,随着深度学习(DeepLearning)人工智能(AI)技术的进步,我们的生活中出现了许多直接有益的应用场景,例如自动翻译精度的提升和根据消费者喜好的个性化推荐。截至2023年,AI在某些领域已经成为产品和服务中不可或缺的应用,其中之一就是自动驾驶(AD)和先进驾驶辅助系统(ADAS)。
以深度神经网络(DNN)为代表的最新人工智能模型的处理需要大规模的并行计算,因此在PC开发中通常使用通用的GPU进行并行计算。另一方面,用于AD和ADAS的SoC多数搭载了专用电路(以下简称加速器),实现了低功耗和高性能的DNN处理。然而,在SoC开发的早期阶段,确认搭载的加速器能否在实际所需的DNN中提供足够的性能通常并不容易。性能比较的指标常常使用加速器设计上的最大计算性能TOPS(Tera Operations Per Second)值,或者其与运行时消耗的功率相除得到的TOPS/W值。然而,由于加速器是针对特定处理的专用设计(*1),即使TOPS值足够高,在实际所需的DNN中也可能由于存在无法高效处理的计算或数据传输带宽不足等问题而无法提供足够的性能。此外,加速器的功率增加可能导致整个SoC的功耗超过可接受的范围。
(*1)专用设计:虽然使用通用GPU作为加速器也是可能的,但处理特定任务的硬件,可以在较小的电路规模和功耗下获得更高的处理性能。例如瑞萨的车载SoC R-Car V3H、R-Car V3M和R-Car V4H搭载的加速器具有专为处理DNN中使用卷积操作进行特征提取的卷积神经网络(CNN)任务而设计的结构。
随着SoC开发的深入,由于性能不足或功耗过大等原因而进行设计变更的难度普遍增加,对SoC开发进度和开发成本的影响也随之增加。因此,在开发面向车载AI设备的SoC时,确认搭载的加速器能否在实际顾客产品中所需的DNN中提供足够的性能,并且功耗是否在可接受范围内,已成为迫切的问题。
面向AD/ADAS的一般AI开发流程
在解释如何解决上述问题之前,先简单介绍一下AD/ADAS的AI开发流程。下面的图1展示了在AD/ADAS中以软件为核心,并包括部分SoC开发的AI开发流程的示例。
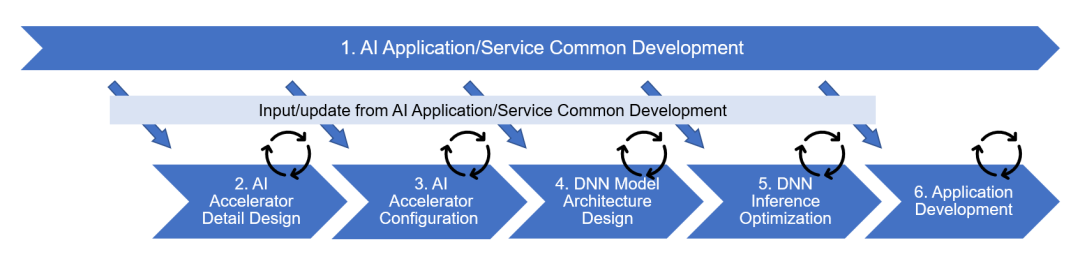
图1:AD/ADAS中AI开发流程的例子
图1将整个开发工作分为六个阶段,其中第2和第3阶段为SoC电路设计,其他第1和第4-6阶段为软件开发。下面给出了每个阶段的工作概述。
第一阶段 AI Application/Service Common Development利用PC和云环境,以应对市场需求和技术趋势,开发面向AD/ADAS的AI应用程序和服务。
第二阶段 AI Accelerator Detail Design
涵盖了构成加速器硬件的部件设计,如计算单元、内部存储器和数据传输单元。
第三阶段 AI Accelerator Configuration
在第三阶段中,第二阶段中设计的组件被组合起来,以优化面积、功率和性能之间的权衡,同时确定加速器在SoC中的配置以实现各自的设计目标。
第四阶段 DNN Model Architecture Design
在第三阶段中确定的加速器配置被用来优化每个用于客户产品的DNN网络的结构。
第五阶段 DNN Inference Optimization
将针对经过第四阶段结构优化的每个网络进行适用于加速器的代码生成,并进行精度和处理时间的详细评估。同时,将对代码和模型数据进行优化,以提高性能。
第六阶段 Application Development
将使用第五阶段中优化的代码和模型数据,将AI处理部分嵌入到实际的自动驾驶等处理中,并进行应用的实现和评估。
瑞萨的工作
在上一节所示的AD/ADAS中的AI开发流程中,判断实际使用的DNN是否能够在所配备的加速器上提供足够的性能,通常需要在决定加速器配置的第三阶段AI Accelerator Configuration中进行决策。
传统上,在这一阶段的决策是通过使用类似加速器的现有SoC进行的基准测试结果来估计的,但对于因增加或改变功能而与现有SoC规格不同的部分,无法获得基准测试结果,因此无法通过高度精确的估计来确定是否能达到设计目标。
瑞萨通过使用PPA Estimator(PPA:Performance,Power,Area)而不是现有的SoC基准测试来解决这个课题。PPA Estimator通过使用反映加速器每个组件设计的性能和功率计算模型,使性能和功耗在加速器配置最终确定之前得到估算。具体来说,列出可能的加速器配置(可改变的加速器参数的组合,如处理单元的数量和内部存储器的容量)进行评估,选择其中一个配置并与要评估的一个DNN一起输入PPA Estimator中,以获得所需的执行时间和功耗。然后,可以针对所需评估的加速器配置和DNN的数量进行重复操作,收集数据,并找到最佳的加速器配置。如此,不仅可以确定一个特定的加速器配置和DNN组合是否有足够的性能,而且还可以收集广泛的数据并从中选择最佳加速器配置。
此外,为了使第三阶段AI Accelerator Configuration更加有效,瑞萨还通过将从PPA Estimator执行结果中获得的信息反馈给目标DNN的网络模型,并行改进软件方面的工作,也就是进行硬件-软件联合设计(co-design)。AI Accelerator Configuration阶段的工作流程如下图2所示。

图2:AI Accelerator Configuration工作流程瑞萨已开始将PPA Estimator应用于从2023年开始的一些带有AI处理加速器的AD/ADAS的SoC的开发中,并计划逐步扩大应用范围。瑞萨将利用PPA Estimator的高度精确性能寻找最佳配置以开发高性能、低功耗的车载AI加速器。

评论排行