
自动驾驶芯片行业研究:中央计算,大模型与领航辅助引领新一轮创新
【ZiDongHua 之汽车驾驶自动化收录关键词: 自动驾驶 汽车芯片 SoC 域控制器 汽车电子】
自动驾驶芯片行业研究:中央计算,大模型与领航辅助引领新一轮创新
复盘:英伟达通用型GPU先声夺人,地平线把握时间窗口进行国产替代
背景:汽车EE架构向集中化演进,催化智驾SoC芯片需求
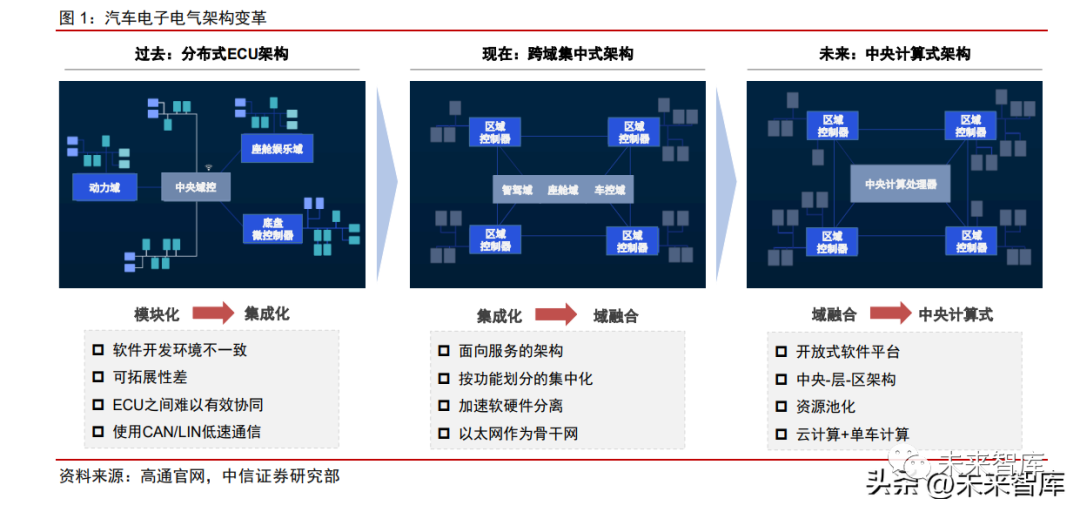
汽车电子电气(E/E)架构从分布走向集中,自动驾驶芯片以SoC为主流。伴随着汽车智能化、网联化、电气化的深入,低效的传统分布式架构已无法满足升级需求,汽车电子电气架构逐渐从分布走向集中,以减少车辆线束,提高内部信息流转效率。传统分布式架构下,汽车各功能模块相互独立,仅需MCU芯片即可满足所需算力。而当电子电气架构向集中式演进,算力亦趋向于集中,仅依靠传统MCU已难以满足计算需求,也因此催化了SoC芯片的发展。当前,自动驾驶芯片以CPU、GPU以及NPU等AI加速器组成的SoC芯片为主流,并作为算力平台集成在域控制器中,从而加速智能汽车走向跨域融合。各大主机厂基于下一代电子电气架构的车型将于2023年起逐步推出。特斯拉在EE架构变革中是引领者,在定义ModelY车型时直接跳过“域集中式EE架构”,直接进化至“中央+区域EEA”的“准中央计算式”。2022款ModelY为中央计算模块CCM+左车身控制模块+右车身控制模块设计,其中CCM(CentralComputingModule)模块整合ADAS(Advanceddriver-assistancesystem)域和座舱娱乐域。当前国内各大传统主机厂与新势力均加速布局,总体看在硬件上采用中央计算+区域控制架构方案,软件上采用SOA(Service-orientedarchitecture)软件架构的设计理念。
我们总结各电子电气架构的特点如下:
分布式:各模块功能划分明确,软硬件强耦合,各模块可独立开发,但无法共用单个SoC,且无法做到冗余,分布式架构需要大量线束支持内部通信,加剧线束成本。此外,各子模块更新需要各供应商提供,迭代效率相对低下。
跨域集中式:将分散的ECU集中至底盘、动力、座舱、智驾域中,从而减少内部通信所需的线束成本,未来将逐步简化为智驾域、座舱域、车控域。此外软硬件可逐步解耦,具备一定后期OTA灵活性。
中央计算式:进一步简化架构,显著降低线束成本,引入SOA化设计开放软件平台,实现软硬件解耦,各功能域共用一个中央计算平台。未来车载计算平台也有望与云计算相结合,实现车-云一体化。同时,中央集中式架构也将真正实现“舱驾一体”,这也对车载SoC芯片提出更高性能、安全等级与集成度的要求。
▍格局:行业格局未定,英伟达引领中高端市场,地平线异军突起
自动驾驶芯片历经10年发展演变,国内格局发生较大变化。我们对其发展历史及格局变化进行复盘,从2014年至今可分为两大阶段:
2014-2018年:玩家以Mobileye、英伟达和传统MCU厂商为主,自动驾驶功能尚处早期,行业内入局者较少。该阶段汽车仍以分布式E/E架构为主,自动驾驶功能等级处于L0-L2,用智能前视一体机即可实现智驾需求,对芯片算力需求不高。Mobileye长期深耕视觉ADAS,自研“视觉算法+芯片”的软硬一体方案,凭借EyeQ3/Q4迎合市场需求,在该阶段占据了L1-L2视觉ADAS芯片市场,营收增速迅猛。同时,传统MCU厂商例如瑞萨、TI等厂商搭载于博世方案,也占据大量市场份额。英伟达以通用GPU架构为基础,于2016年推出TegraParkerSoC,搭载于特斯拉HW2.0平台,正式将GPU路线的自动驾驶SoC推向市场,但该阶段的智驾SoC技术迭代仍较慢。
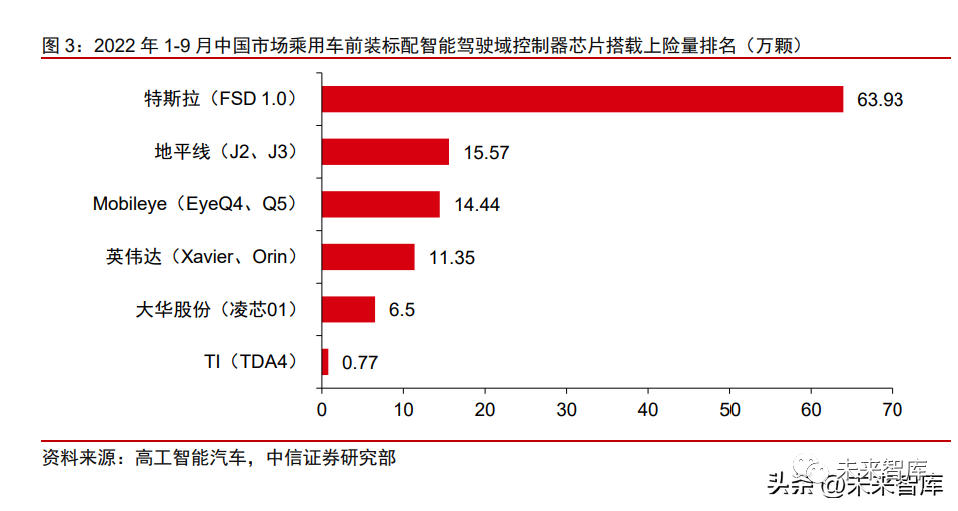
2019-2022年:行业发展提速,英伟达引领高算力市场,地平线抓住时间窗口进行国产替代。2019年,特斯拉第一代自研FSD芯片成功,车企开始重视打造软硬结合的自动驾驶能力,自动驾驶芯片行业亦进入快速发展期。在低算力(30TOPS以下)市场,地平线抓住时间窗口进行国产替代,逐渐抢夺Mobileye的市场份额。2019年,地平线抢先发布J2芯片(4TOPS),并于2020年实现量产,搭载于长安主力车型UNI-T。2021年,汽车行业缺“芯”导致车辆减产,国内车企开始重视国产芯片供应商的培养。地平线于当年实现了J3芯片(5TOPS)的量产,自此在自动驾驶领域积累了先发优势,并凭借更开放的生态逐步侵蚀Mobileye在国内的市场份额。据高工智能汽车(微信公众号,除非特别说明,下同)数据,2022年1-9月,地平线在中国市场乘用车前装标配智能驾驶域控制器芯片的出货量已跃居第二,仅次于特斯拉,Mobileye则跌至第三。除地平线和Mobileye外,TI、赛灵思、瑞萨等芯片厂商的SoC亦占有一席之地。
在中高算力(30TOPS及以上)市场,英伟达基于领先的GPU架构先声夺人,地平线则有望将国产替代的脚步带向中高端市场。英伟达2020年针对L2市场发布Xavier芯片(30TOPS),搭载于小鹏P7/P5等车型;2022年又推出大算力Orin芯片(256TOPS),再次引领行业占据主流中高端车型市场,是此前所有瞄准L2+高阶辅助驾驶车型的选择。而地平线于2022年推出J5芯片(128TOPS)并上车理想,希望以更高的性价比和更优的本土化服务与英伟达展开同台竞技。此外,高通、黑芝麻、辉羲智能等一众玩家也将于今明两年正式加入中高算力芯片的角逐赛。
▍展望:小算力芯片需求保持强劲,大算力芯片走向更新架构
中短期车企智能化策略因产品定价出现分化,算力需求有所不同
中短期来看,随着今年车企价格战的打响,前几年一味堆料堆硬件的趋势将告一段落,务实和高性价比将是决赛圈存活的关键。也因此,车企智能化策略或因产品定价出现分化:
1)10-20万元车型:追求高性价比智驾方案,算力需求在5-30TOPS。特斯拉降价导致国内车企成本压力倍增,加速行业洗牌。我们认为,成本压力下,10-20万元的低端车型倾向于追求高性价比智驾方案,中短期内仍将以传统的L2功能为主,部分车型或可提供基本的高速领航功能,算力需求在5-30TOPS。传统L2功能仅需10TOPS左右即可满足需求。而高速领航作为L2+的代表功能,算力配置亦在下探。尽管在安全冗余性和体验流畅度上或有所欠缺,但也可满足功能的基本需求。但业内普遍认为,高速领航若想要“好用”,即提供更高的冗余性和更平滑流畅的驾驶体验,仍需更高算力的支持,30-60TOPS的中算力芯片或更为合适。
2)20-30万元车型:高速领航渐成标配,降本压力下车企对硬件配置趋于理性,判断算力需求在30-80TOPS。处于该价格带的车型,一方面面临特斯拉Model3/Y的直接竞争,成本压力尤为明显;另一方面也需一定的智能化程度以打造差异化特征。我们认为,高速领航有望逐渐成为此价格带车型标配,且相较于低端车型,可以以相对更高的硬件配置提供更优的驾乘体验,但车企在降本压力下也将趋于理性,不再一味堆砌硬件和算力,因此预计算力配置将普遍上升至30-80TOPS,中算力芯片有望成为主流选择。
3)30万元以上车型:追求更佳的智能化体验,芯片走向大算力&新架构。我们认为,30万元以上的高端车型受价格战影响相对较小,主机厂追求打造标杆性的智能化标签,或将持续发力城区领航,当前算力配置普遍超200TOPS。为了实现效果更佳、体验更优的领航功能,“BEV+Transformer”开始引领自动驾驶感知范式;长期看,“舱驾一体”也有望成为智能汽车E/E架构演变的终局。在上述两大技术趋势的驱动下,自动驾驶芯片开始走向大算力&新架构。
小算力芯片:量产交付、安全稳定和性价比是关键,地平线和TI领先地位较为稳固
中短期来看,小算力芯片有望伴随L1-L2功能的快速增长进入规模放量阶段。我们认为,车企将更倾向于量产经验丰富、交付能力强、安全稳定性高且性价比突出的芯片厂商,地平线和TI当前领先地位较为稳固,但仍有新玩家持续入场。过往辅助驾驶以基础L0-L2功能为主,智能前视一体机即可实现,以Mobileye、博世、大陆、赛灵思的方案为主。而伴随轻量级行泊一体以及基础高速领航功能渗透率的提升,我们认为,集成SoC芯片的小算力域控平台将成为主流。由于小算力芯片的技术壁垒和架构难度较中高算力更低,因此我们认为,芯片厂商的量产交付能力、安全稳定性和性价比将成为车企关注的重点。
地平线凭借先发优势、生态圈建立和本土化服务有望持续走在国内小算力芯片市场的前列;TI主推的TDA4VM在功能完整度和车规可靠性上有较大优势,且实现了小算力芯片中少有的单SoC行泊一体方案,有望持续保持高竞争力。
Mobileye由于黑盒方案难以满足行泊一体等开发需求,未来或仍将主要针对L1-L2需求,将成熟的感知算法内嵌至芯片中打包出售,对自研能力较弱的车企更为友好。此外,以芯驰科技、寒武纪以及爱芯元智为代表的厂商,此前在其它应用场景积累了较为丰富的量产交付经验,未来亦有机会切入智驾芯片市场,对地平线和TI形成竞争压力。
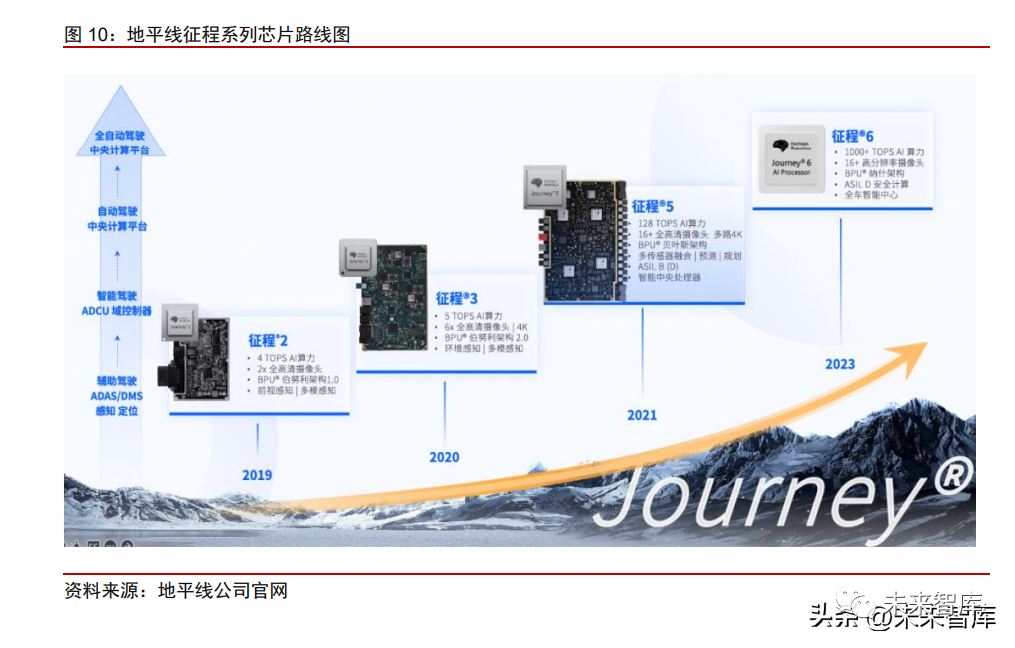
地平线:J2/J3率先卡位小算力芯片市场,具有先发优势,有望持续受益于国产替代浪潮,走在国内小算力芯片市场的前列。抓住国产替代时间窗口,具有先发优势,本土化服务能力领先。地平线J2/J3芯片分别具备4/5TOPS算力,在推出时瞄准Mobileye所在的ADAS市场,且相比于MobileyeEyeQ4具备更高算力与开放性,因此凭借芯片产品力、较完善的工具链以及本土化服务能力,在供应链安全可控背景下,迅速受到众多有软件算法自研需求的本土车企青睐。
TI:TDA4VM在架构完整度和功能安全性方面占优,有望成为10-20万车型轻量级行泊一体方案的主流选择之一。TDA4VM算力高于J3和EyeQ4,可实现单SoC轻量级行泊一体方案。TI于2020年推出核心产品TDA4VM,算力8TOPS,高于地平线J3(5TOPS)和MobileyeEyeQ4(2.5TOPS),且供货稳定。当前,大疆、MAXIEYE、Nullmax、禾多科技、纵目科技等玩家都在基于TDA4开发行泊一体方案。
架构完整且集成度高,利于车企和方案商进行二次开发。TDA4采用多核异构架构,集成了ARMCPU、数字信号处理器(DSP)、深度学习加速器(DLA)、MCU等单元,由对应的核或者加速器处理如逻辑算力和AI算力等不同任务。TI的AI算力来自于自研矩阵乘法加速器MMA(可类比地平线的BPU),能够提供较灵活的矩阵乘法运算,通用性介于GPU和ASIC之间,因此拥有更强的可扩展性与并行处理能力。值得一提的是,TDA4是业内为数不多内置ASIL-D级MCU的智驾SoC。由于大多智驾SoC还无法满足高功能安全等级的要求,因此常见做法是在智驾域控主板上外挂一颗独立的MCU芯片,比如英飞凌TC297/397等,以提供状态监控、整车底盘控制、执行最小安全风险策略等。为了简化系统设计、缩短通讯延时、节省硬件成本,部分芯片厂商开始在SoC内部内置MCU核心(功能安全岛SafetyIsland)。TI的TDA4系列就是内置MCU的典型代表,其MCU为ASIL-D级ArmCortex-R5F,进行了单独电压和时钟设计,采用专用内存和接口确保其与SoC其余部分隔离,因此车企无须再外接MCU进行开发。尽管内置MCU已成趋势,但与成熟稳定的传统外挂MCU相比,内置安全岛的功能安全性、实时性和可靠性在实际应用中仍有一定差距。因此,域控厂商在使用地平线J3、黑芝麻A1000等芯片时,多数情况下仍会选择外挂一个MCU提供安全冗余。
但TI的相对劣势在于,由于集成了GPU、MMA、DSP等众多处理单元,TDA4VM在高负载下功耗可高至20W,对Tier1与主机厂在散热等方面的工程化能力提出了较高的要求。此外,相比于纯ASIC路线,TI在特定算法上的运算效率或不及地平线。
Mobileye:传统视觉ADAS龙头,因黑盒模式和迭代较慢,市场份额正在被地平线等其他玩家快速侵蚀。但其“视觉算法+芯片”的智能前视一体机方案具备高性价比,未来或将主要针对L1-L2需求,对自研能力较弱的车企更为友好。因黑盒模式和迭代较慢,市场份额正在被快速侵蚀。Mobileye是昔日ADAS领域的主要奠基者和引领者,提供算法+EyeQ系列芯片组成的一体化软硬件解决方案。在Mobileye方案的帮助下,车企可高效且高性价比地适配L1-L2级基础辅助驾驶功能。但随着汽车智能化程度的提升,车企开始希望对自身的智能化方案有更高的话语权和主动权,而Mobileye的全栈黑盒模式已无法满足大多数车企的自研需求。此外,区别于主流CPU架构(ARM、X86),Mobileye的EyeQ4芯片采用多MIPS处理器,导致其通用性和可开发性较差,难以形成良好的软件生态。因此近年来,Mobileye智能一体机方案吸引力开始下降。面对危机积极寻变,逐步开放生态,但竞争格局远较此前激烈。2021年,Mobileye推出EyeQ5芯片,首次提供单芯片(silicon-only)版本,开放SDK、OpenCL环境和TensorFlow,从而允许客户部署自研算法,但目前EyeQ5芯片也仅收获极氪一家定点。自动驾驶芯片的竞争环境日益激烈,海内外众多车企正在将平台从MobileyeEyeQ系列迁移至英伟达、地平线、华为、高通等其它玩家。我们认为,Mobileye“视觉算法+芯片”的智能前视一体机方案仍具备高性价优势,对自研能力较弱的车企更为友好。但随着汽车智能化能力逐步提升,后续能否跟进主机厂快速迭代的需求并进一步开放生态,将是Mobileye不掉队的关键。
黑芝麻:基于A1000L打造行泊一体方案,获一汽红旗下一代FEEA3.0架构车型定点,但相关车型规划2024年SOP,时间点上相较地平线和TI不占优。公司早在2020年就推出了A1000L芯片,搭载8核ARMCortexA55CPU、ARMGPU、3核高性能DSP、CV加速引擎,以及自研DynamAINN引擎,AI算力达16TOPS,具备业内领先的功能完整性与计算性能。基于A1000L芯片打造的DriveSensing解决方案可实现单SoC芯片的行泊一体方案,支持L2+高速领航NOA、泊车HPA/AVP、3D360环视全景、多路DVR等功能。2023年5月,公司宣布A1000L获得一汽红旗下一代FEEA3.0电子架构平台项目量产智驾芯片定点。一汽红旗将基于A1000L打造非分时复用的行泊一体自动驾驶域控平台,该平台将应用于一汽红旗80%左右的车型,其中一汽红旗E001和E202两款车型最快将于2024年量产落地。核心竞争力来自两大自研IP:图像信号处理ISP以及神经网络加速器NPU。ISP负责“看得清”,可处理摄像头采集的每一帧原始图像数据;NPU负责“看得懂”,通过集成图像分类、空间分割、特定目标分析等多个功能到单个神经网络,可实现结构化剪裁,从而帮助黑芝麻芯片提升神经网络运算能力并降低功耗。
爱芯元智:在智慧城市领域积累了丰富的交付经验和完善的工具链,有望借此切入小算力智驾芯片市场。爱芯元智成立于2019年,截至目前已成功推出了两代四颗端侧、边缘侧AI视觉感知芯片,并实现大规模量产供货。目前爱芯元智的主要下游为智慧城市业务,例如智慧物联领先方案商大华股份就是爱芯元智的重要客户之一,爱芯元智自主研发的芯片AX630A和AX620A已作为主控SoC应用于大华股份多个产品线,并获评大华股份2021年战略供应商。基于自有ISP与NPU的联合架构设计,爱芯元智可大幅提升传统ISP中多个关键模块的性能,实现高能效比和高算力利用率。目前,公司也开始进军智能驾驶领域,2022年8月参与投资ADAS解决方案商MAXIEYE,后续二者或有上车合作。我们认为,爱芯元智在智慧城市领域积累的量产经验和搭建的工具链可赋能智驾业务,尤其是在小算力芯片市场,车企将更看重供应商的交付能力以及产品的易开发性。2019至2022年,爱芯元智完成了近20亿元的融资,投资方包括美团、美团龙珠资本、腾讯投资、联想之星等互联网巨头,以及启明创投、GGV纪源资本、耀途资本等知名机构。
芯驰科技:座舱芯片对标高通,丰富的量产经验与车企合作生态有望助力智驾芯片适配上车,但内部资源在不同产品线间的合理化分配是关键。芯驰科技成立于2018年,作为国内少有的“全场景、平台化”的芯片和技术解决方案供应商,产品包括域控芯片E3、座舱芯片X9、智驾芯片V9和网关芯片G9。公司当前除智驾芯片外,其余三款芯片已实现大规模量产。尤其是在智能座舱芯片领域,公司X9系列座舱芯片能够在性能上对标高通。我们认为,芯驰在座舱芯片积累的量产交付经验与产业链生态建设有望助力其智驾芯片的渗透,但座舱芯片和智驾芯片在产品架构和软件算法上仍有较大不同,即使是高通目前在智驾领域的进展也并不如人意,且作为初创公司,能否在不同产品间合理分配有限的资源目前来看仍待验证。
寒武纪行歌:母公司寒武纪丰富的AI芯片技术积累有望迁移至车端,云边端一体化统一生态架构,有助于构建车端推理-云端训练闭环。寒武纪行歌成立于2021年,作为寒武纪控股的子公司,行歌专注于自动驾驶芯片研发,目前在研数款智驾芯片,覆盖L2-L4:1)已接近量产的SD5223针对L2+行泊一体方案,具备高能效比,相较于TDA4VM算力提升一倍(16TOPS)。2)基于SD5223,寒武纪推出低算力低功耗的SD5223C,算力6TOPS,支持8M前视一体机和自动泊车功能,或有望渗透传统Mobileye占据的前视一体机市场。3)公司也表示未来将推出面向L4市场的SD5226,规划算力超400TOPS,300K+DMIPS,采用7nm制程,并支持车端训练,亦有望进军中高算力芯片市场,但也须留意公司芯片代工或受地缘政治因素影响,从而影响实际量产时间。寒武纪行歌自成立以来,已与经纬恒润、一汽等签订了自动驾驶合作协议,并累计获得了上汽、蔚来、宁德时代、博世创投等重磅产业资本加持,待产品技术打磨成熟,芯片有望快速实现量产。
中算力芯片:高速领航带来发展机遇,各玩家皆有突围可能
中算力芯片(30-100TOPS)市场此前相对空白,以英伟达Xavier为主。但随着车企趋于理性,中端车型不再一味参与大算力芯片军备竞赛,但同时又希望实现较优的高速领航功能,中算力芯片需求有所上升。目前来看,英伟达Xavier和OrinNX/Nano、TITDA4VH以及黑芝麻A1000已瞄准该市场开始出击,但同时也不排除地平线等其他厂商未来推出对应产品以完善产品矩阵的可能性。因此整体而言,我们认为,中算力芯片市场的较量才刚刚开始。与小算力和大算力相比,中算力市场或对芯片厂商的综合能力有更高要求,场内现有玩家皆有突围可能。
英伟达:Xavier和OrinNX有望占据中算力市场较大份额。2020年,英伟达针对L2市场发布Xavier芯片(30TOPS),搭载于小鹏P7/P5等车型;2022年又推出大算力Orin芯片(256TOPS),再次引领行业占据主流中高端车型市场,是此前所有瞄准L2+高阶辅助驾驶车型的选择。但随着行业回归理性,Orin对于大部分20万-30万元的中端车型配置或过高,英伟达也因此通过硬件陆续推出OrinNX(70/100TOPS)和OrinNano(20/40TOPS),完善自身产品矩阵。鉴于OrinX当前已成功上车众多车型,经过量产可靠性验证,我们认为,较低配的OrinNX和Nano系列也有望共享同一套英伟达开发工具链与生态,以切入主流车企的中端车型市场。
黑芝麻:A1000芯片算力58TOPS,精准填补50-100TOPS芯片市场空缺,我们预计2023年上车江淮思皓与领克08。GPU方面,A1000自带GPU,能够针对泊车场景进行环视算法拼接,从而支持单芯片的行泊一体方案,对比地平线J5需外挂负责3D渲染的GPU。CPU方面,A1000搭载八核ARMCortexA55,具备多级缓存,能够适应大量数据的预处理工作。CV加速方面,A1000包含5核DSP芯片,其中4核可以供客户进行调用,因此释放给客户的CPU资源也更为充裕,对比J5只含双核DSP。由于很多算法设计需要大量用到CPU性能调度,因此A1000或更利于客户灵活开发部署算法。得益于较高的功能完整性,A1000打造的行泊一体等方案性价比较高。公司2023年4月宣布将推出BOM成本3000元以内的行泊一体域控方案,支持10V配置和50-100TOPS物理算力。
TI:TDA4系列向中算力进军以完善产品矩阵,已与主流Tier1达成合作。此前行业众多Tier1已基于TDA4VM顺利开发面向L2场景的域控,TDA4VM也已成为单SoC轻量级行泊一体方案的主流选择之一。TDA4VM由于算力相对有限(8TOPS),因此实现的为“分时复用”的行泊一体方案,传感器配置为5V5R或6V5R,而基于单TDA4VH(32TOPS)或TDA4VMPlus(24TOPS)可实现非分时复用行泊一体方案,支持例如10V5R的更高阶传感器方案,以帮助TI进一步渗透L2+市场。我们认为,得益于TDA4VM在小算力市场的成功,TI不仅积累了丰富的量产经验,车企也可使用同一套工具链以实现更低的迁移和开发成本,因此TI在中算力市场亦有一定优势。当前德赛西威、福瑞泰克、百度等厂商已宣布将基于TI中算力SoC开发域控,其中福瑞泰克ADC30域控基于2颗TDA4VH和3颗地平线J5,公司预计2023年量产。
大算力芯片:BEV/Transformer+舱驾一体驱动芯片走向大算力&新架构
在“BEV+Transformer”以及“舱驾一体”两大技术趋势的驱动下,自动驾驶芯片开始走向大算力&新架构。目前来看,英伟达和高通走在变革前列,地平线量产进度领跑国内市场,华为MDC或涅槃归来,架构变化下辉羲智能等国产厂商亦有突围机会。
趋势1:城区领航年内开始上车,“BEV+Transformer”引领自动驾驶感知范式。在此趋势下,算法复杂度、数据规模以及模型参数均呈指数级提升,由此对车载自动驾驶芯片的AI算力、数据吞吐量与架构创新也提出了更高的要求。
小鹏、华为领衔,城区领航年内开始落地。目前,城区领航尚处发展早期,小鹏和华为的方案已于2022年9月开始落地,并在逐步拓宽开放区域。小鹏城市NGP(NavigationGuidedPilot)功能自2022年9月率先于广州进行试点,2022年10月于广州全量推送;2023年3月17日,小鹏宣布城市NGP功能向深圳地区开放,后又拓展至上海。北汽极狐和长安阿维塔均选择HI(HuaweiInside)模式,依靠华为ADS高阶自动驾驶全栈解决方案打造城区NCA功能,分别命名为α-Pilot高阶智能驾驶辅助及AVATRANS智能领航系统。极狐城区NCA已开通深圳、上海及广州三地,覆盖车型为极狐阿尔法S全新HI版。阿维塔也于2023年3月9日宣布在上海及深圳开启城区NCA(NavigationCruiseAssis)试驾体验,覆盖车型为阿维塔11,广州、重庆两地也即将开放体验。除此之外,根据各公司公告,理想、集度、长城等车企也计划在2023年推出各自的城区领航功能。
城区领航被视为L4级自动驾驶功能在乘用车上的极致演绎,实现难度和壁垒远高于高速领航,当前算力需求普遍超200TOPS。尽管在系统训练层面,自动驾驶95%的底层架构和基础问题已经解决,但最后5%的长尾问题,也就是cornercases的存在,是制约无人驾驶实现的最大瓶颈之一。与场景较为规则、工况较为单一的高速领航相比,城区领航路口多、变道多、拥堵多,cornercases的数量和复杂程度大幅提升,不仅涉及异型车、行人、路障等多类别主体,且存在加塞、“鬼探头”、前车急停等非规律行车现象。据小鹏在2022年1024科技日上的介绍,城市NGP的代码量是高速NGP的6倍,感知模型的数据是高速NGP的4倍,预测/规划/控制相关的代码是高速NGP的88倍。
城区领航对自动驾驶感知算法提出了更高的要求,“BEV+Transformer”范式粉墨登场。大模型是当前AI领域最为火热的前沿趋势之一,可赋能自动驾驶领域的感知、标注、仿真训练等多个核心环节。在感知层,以特斯拉为首,“BEV+Transformer”范式已开始在自动驾驶领域得到广泛使用,可有效提升感知精确度,利于后续规划控制算法的实施,促进端到端自动驾驶框架的发展。
BEV全称Bird’sEyeView,即鸟瞰图,该算法旨在将多传感器收集的图像信息投射至统一3D空间,再输入至单一大模型进行整体推理。相较于传统的摄像头图像,BEV提供了一个更贴近实际物理世界的统一空间,为后续的多传感器融合以及规划控制模块开发提供了更大的便利和更多的可能。具体来说,BEV感知的优势在于:
1)统一了多模态数据处理维度,将多个摄像头或雷达数据转换至3D视角,再做目标检测与分割等任务,从而降低感知误差,并为下游预测和规划控制模块提供更丰富的输出;
2)实现时序信息融合,BEV下的3D视角相较于2D信息可有效减少尺度和遮挡问题,甚至可通过先验知识“脑补”被遮挡的物体,有效提高自动驾驶安全性;
3)感知和预测可在统一3D空间中实施,通过神经网络直接完成端到端优化,可有效降低传统感知任务中感知与预测串行的误差累积。
Transformer的注意力(Attention)机制可帮助实现2D图像数据至3DBEV空间的转化。Transformer是GoogleBrian团队在2017年提出的神经网络模型,起初用于机器翻译,随着技术的发展开始进军图像视觉领域,目前已成功涉足分类、检测和分割三大图像问题。据汽车之心微信公众号介绍,传统CNN模型的原理是通过卷积层构造广义过滤器,从而对图像中的元素进行不断地筛选压缩,因此其感受域一定程度上取决于过滤器的大小和卷积层的数量。随着训练数据量的增长,CNN模型的收益会呈现过饱和趋势。而Transformer的网络结构在嫁接2D图像和3D空间时借鉴了人脑的注意力(Attention)机制,在处理大量信息时能够只选择关键信息处理,以提升神经网络的效率,因此Transformer的饱和区间很大,更适宜于大规模数据训练的需求。在自动驾驶领域,Transformer相比于传统CNN,具备更强的序列建模能力和全局信息感知能力,目前已广泛用于视觉2D图像数据至3D空间的转化。
在“BEV+Transformer”趋势下,算法复杂度、数据规模以及模型参数均呈指数级提升,推动自动驾驶芯片向着大算力、新架构以及存算一体等方向演进。
1)大算力:向数百TOPS算力演进。传统L1/L2辅助驾驶所需处理的数据量小且算法模型相对简单,因此以Mobileye为代表的单目视觉+芯片算法强耦合的一体机方案即可满足需求。但领航功能作为高阶辅助驾驶的代表,需要“更强算力+软硬件解耦的芯片+域控制器”来满足海量数据处理与后续持续OTA迭代的需求。高速领航开始向20万元以下车型渗透,15-30TOPS可满足基本需求,但若想要“好用”或需要30-80TOPS。城区领航的场景复杂程度和技术实现难度更高,目前普遍需要搭载激光雷达,芯片以英伟达Orin、华为MDC和地平线J5为主,算力配置普遍超200TOPS。而在应用“BEV+Transformer”技术后,多传感器前融合以及2D至3D空间的转化需要AI芯片具备更强的推理能力,因此也需要比以往更大的算力支撑,包括更高的AI算力、CPU算力和GPU算力。
2)新架构:加强并行计算能力和浮点运算能力。相较于CNN/RNN,Transformer具有更强的并行计算能力,可加入时间序列矢量,其数据流特征有显著差别,浮点矢量矩阵乘法累加运算更适合采用BF16精度。Transformer允许数据以并行的形式进行计算,且保留了数据的全局视角,而CNN/RNN的数据流只能以串行方式计算,不具备数据的全局记忆能力。传统AI推理专用芯片大多针对CNN/RNN,并行计算表现不佳,且普遍针对INT8精度,几乎不考虑浮点运算。因此想要更好适配Transformer算法,就需要将AI推理芯片从硬件层面进行完整的架构革新,加入专门针对Transformer的加速器,或使用更强的CPU算力来对数据整形,这对芯片架构、ASIC研发能力以及成本控制都提出了更高的要求。
3)存算一体:SoC芯片需配置高带宽存储器(HBM)或SRAM,并加速向存算一体靠拢,解决大算力下的数据吞吐量瓶颈。模型越大,内存对AI加速器就越重要,以频繁地读取权重矩阵或训练好的模型参数。据佐思汽研介绍,Transformer中的权重模型超过1GB,对比传统CNN的权重模型通常不超过20MB。模型参数越大,就需要更高的带宽,一次性读出更多参数。存算一体可分为近存计算(PNM)、存内处理(PIM)以及存内计算(CIM),存内计算则接近存算一体。当前PNM已广泛用于高性能芯片,即采用HBM堆叠,2.5D封装,从而与CPU集成,而PIM和CIM仍处在发展中。以特斯拉FSDSoC为例,其采用总带宽为68GB/s的8颗LPDDR4内存,而集成在NPU中的SRAM可达到32MBL3缓存,带宽达2TB/s,远超市面上同类芯片。而据汽车之心微信公众号,特斯拉在最新HW4.0上的二代FSDSoC上使用了16颗GDDR6,在内存用料上继续引领行业。
趋势2:长期来看,伴随跨域融合+中央计算式趋势,支持“智能驾驶+智能座舱”的舱驾一体多域计算控制架构或成为终局需求,我们预计2025年后开始初步量产上车。舱驾一体可有效降低开发成本和通讯延时、优化算力利用率和功能体验,推动智能汽车应用迈上新的台阶。高工智能汽车统计,2022年1-10月中国乘用车前装同时标配“L2级辅助驾驶+智能座舱+车联网+OTA”的搭载率达18.01%;且预测至2025年同时标配“智能驾驶+智能座舱”的交付车辆有望突破350万辆。我们总结舱驾一体的主要优势在于:
降低成本:物料方面,相比于多SoC方案,单芯片集成度更高、使用物料更少,且共用一套散热系统带来散热成本下降。开发方面,当前智能化的实现仍需要车企在不同的芯片组合之间进行挑选,由此带来硬件及软件开发的多平台成本消耗,而使用单SoC可以节约此类额外的开发成本和多供应商的隐性采购管理成本,部分底层软件的共用也可降低不同平台车型的上车速度和软件开发成本。
降低通讯延时,优化功能体验:使用单颗SoC可使舱和驾之间数据传输从板间通讯变为片内通讯并共享内存,从而降低通讯延时,实现更流畅的舱驾功能。例如英伟达ThorSoC支持所有显示器、传感器集成至单一SoC,极大简化了汽车制造的复杂程序,并有助于传感器数据更及时充分地复用,实现更流畅的汽车智能化功能。
但“舱驾一体”距离真正实现仍有一定距离,软硬件技术和工程化皆面临挑战。一方面,座舱和智驾面向的应用场景、功能定义、性能边界不一样,如若融合在一起,芯片选型、外围电路设计、算力需求重点以及安全等级要求都不同,因此成本和性能的平衡难度较大。另一方面,当前绝大部分厂商受限于软硬件技术、对整体架构的理解和供应链等因素,在技术上难以实现单SoC集成座舱和智驾功能。因此当前,更多厂商仍采用“多颗SoC+多域控制器”方案。部分厂商已在单个域控制器中将座舱和智驾SoC部署在不同主板或同一个主板。例如特斯拉是“中央计算+区域控制”理念的最早实践者,基于全系统架构自研,能够理清座舱、智驾和整车控制等系统之间的关联,并在前期充分预留接口。早在2019年量产的Model3车型中,中央计算单元CCM就融合了影音娱乐模块(座舱)、驾驶辅助系统模块(智驾)以及车内外通信模块,共用一套液冷系统。但这三个模块仍分别部署在不同的PCB板上,各自独立运行操作系统,因此并不算严格意义的舱驾一体核中央集中式架构。想要实现真正的舱驾一体,即单SoC部署在单PCB板,仍需要软硬件技术与工程化能力的不断提升。
我们认为,待EE架构进化到中央集成计算架构阶段,且业内逐渐完成底层软硬件铺设,舱驾一体或有望在2025年后开始上车,同时推动自动驾驶SoC芯片走向以下趋势:
1)大算力:向上千TOPS演进,包括CPU算力、GPU算力与AI算力。CPU主要负责逻辑运算和决策控制,需要同时负责智驾域和座舱域系统调度、数据处理与指令运算,随着舱驾一体化下数据处理量增大,CPU需要更大的算力支撑。GPU擅长图像渲染、图形处理以及大规模并行AI计算,随着自动驾驶等级不断提升、座舱娱乐趋向大屏多屏化以及人机交互功能逐步强化的背景下,GPU算力需求也将不断提升。此外,当前自动驾驶SoC普遍会在CPU和GPU基础上搭载AI加速器,例如神经网络处理器NPU。根据公司公告,英伟达Thor和高通SnapdragonRideFlexSoX均规划2025年左右量产,面向舱驾一体化场景,算力达2000TOPS。
2)先进制程:可能采用Chiplet技术。要实现舱驾一体需要高算力支撑(通常超1000TOPS),并需要将功耗控制在合理范围,自动驾驶芯片需要向更先进制程方向发展,从而在相同面积晶圆下放置更多计算单元,提供额外的算力。当前车载AI芯片已下探到5nm,但掌握先进工艺的企业较少,中国本土厂商还面临台积电产能限制问题。例如地平线J5就仍采用16nm,一方面是使用了功耗/算力比更优的ASIC,另一方面或也做了国产代工的两手准备。在此背景下,Chiplet技术有望成为智驾芯片实现性能跨越的重要路径,满足算力、效率与功耗不断提升的需求。Chiplet又叫小芯片/芯粒,通过将多个小芯片与特殊封装技术相结合,构成更大的IC。相比于直接生产单SoC,使用小芯片生产有助于提升晶圆面积利用率,且小芯片可以重复利用,从而降低产品总设计和验证成本。此外,采用Chiplet技术后,各大厂商可以专注于自己的芯粒和IP,省去多余的IP费用。小芯粒的流片良率也普遍更高。但需要注意的是,Chiplet技术仍面临产业链成熟问题和座舱和智驾融合的工程化难题,当前仍处在发展过程中。而对于中国公司,Chiplet技术中的小芯片仍大量采购自海外巨头,因此国产替代的逻辑相对有限。
3)新架构:分域隔离。座舱和智驾域功能集成在单SoC时,由于两个域需求不同,在做硬件资源分配时,既要定义应用的优先级,又要确保各自有足够的资源,这对底层的芯片架构提出了更高要求。同时,智驾与座舱域安全等级不同,所跑的操作系统也不同,需要做好安全隔离,确保不同应用的功能安全和信息安全,当前座舱娱乐模块需要达到ASILA,仪表模块需要达到ASILB,而行车模块需要达到ASILD,这对芯片底层的加速器资源如何进行有效隔离也是比较大的挑战,同时舱驾融合需要在操作系统层面做虚拟化技术,也会带来额外硬件开销,但也确保了各域之间功能与信息安全性。
英伟达:基于GPU高技术壁垒,长期引领智驾芯片技术革新。OrinX是当前唯一量产且算力超200TOPS的大算力芯片,占据了主流中高端车型智驾芯片最大市场份额。2022年9月,英伟达又发布ThorSoC,算力达到2000TFLOPS@FP8,面向中央计算式架构设计,支持云端融合、一芯多用、跨域计算,被认为定义了行业未来3年的发展方向,规划2025年量产,已宣布极氪为首发车型。针对BEV+Transformer:英伟达在HopperGPU架构中加入Transformer推理引擎,大幅提升AI运算效率。GPU天生适合Transformer模型所需的浮点运算以及高带宽需求,而英伟达又在Thor的HopperGPU架构中加入了Transformer推理引擎,进一步提升其AI运算效率。该Transformer引擎于2022年已被英伟达集成于H100训练服务器中,采用英伟达HopperTensorCore技术,能够应用FP8和FP16混合精度,以大幅加速Transformer模型的AI计算,采用FP8的TensorCore运算在吞吐量方面是16位运算的两倍。此外,Thor也旨在统一训练和推理端的精度,Transformer引擎在用于推理时,无需进行任何数据格式转换,能够以FP8输出结果。此前英伟达、英特尔与ARM三家联合推出FP8格式标准,当前多数自动驾驶模型训练由英伟达芯片完成,若能够做到训练与推理端统一使用FP8,则效率和准确度将大幅超越INT8,因此Thor有望成为英伟达训练芯片客户的首选推理端SoC。值得一提的是,英伟达取消了2021年GTC大会上所发布的Atlan,我们认为主要原因之一就在于Atlan或没有考虑Transformer专用引擎且不支持FP8格式。
针对舱驾一体:英伟达ThorSoC提出“单芯片解决一切”,算力一骑绝尘,架构持续引领行业。Thor可以借助NV -C2C技术整合GraceGPU、HopperGPU与次世代GPU(ARM最新服务器CPU架构V2或波塞冬平台),实现2000TOPS的FP8效能,并支持单SoC实现座舱与智驾等功能。DRIVEThor能够进行多域计算,可以将自动驾驶、车载信息娱乐等功能划分为不同任务区间,同时运行,互不干扰,并能够将所有显示器、传感器计算需求集中至单SoC。多计算域隔离能力,可支持时间关键型的进程不间断同时运行,在单SoC上可以同时运行Linux、QNX和Android,未来主机厂可以借助Thor隔离特定任务的能力,告别分布式的电子控制单元,整合全车功能。
高通:立足智能座舱,有望迅速跻身自动驾驶第一梯队。针对智能座舱市场,高通凭借骁龙SA8155迅速抢占中高端市场,SA8295继续代表座舱SoC最前沿技术。而针对自动驾驶市场,高通凭借SnapdragonRide自动驾驶平台以及去年发布的SnapdragonRideFlexSoC打响进军高性能自动驾驶芯片的发令枪。针对BEV+Transformer:基于消费电子与智能座舱领域积累的芯片开发经验,在CPU算力、浮点运算能力以及内存带宽上持续突破,顺应Transformer上车趋势。高通2020年初推出SnapdragonRide自动驾驶平台,配备SA8540PSoC和AI加速器SA9000P,提供若干SoC和ASIC组合的方案,可覆盖ADAS到L4的算力需求(10-700+TOPS)。据佐思汽车研究微信公众号上发表的文章《高通自动驾驶平台SnapdragonRide分析》(周彦武),SnapdragonRide中的SA8540或是骁龙865的车规版,而S9000或是云端加速芯片CloudAI100的车规版。骁龙865搭载Adreno650GPU,全面提升16位/32位浮点运算能力,并特别加入Hexagon698张量加速器,具备Transformer模型下车端的高效AI推理能力。而CloudAI100则特别针对AI大模型推理打造,能够提供400TOPS的算力,峰值性能是Snapdragon855和Snapdragon820的3到50倍,与传统的FPGA相比推理速度提高约10倍,且在AI推理的每瓦能效上超越英伟达A100。
地平线:地平线J5是目前唯一规模化量产的国产大算力芯片,拥有128TOPS算力,30W低功耗,领先同级竞品的1531FPS(真实计算性能)以及60ms超低延迟感知能力。基于规模异构近存计算、高灵活大并发数据桥及脉动张量计算核三大核心技术,J5能以更少内存、更高MAC利用率执行更多任务,将并行计算发挥到极致,提升算力有效利用率。这也利于芯片在不堆叠面积和有限功耗下,发挥最多的实际AI性能。J5在EfficientNet模型测试中,FPS指标优于英伟达Orin和Xavier。当前J5已经上车理想L7、L8Pro等高端车型,未来有望进一步占据英伟达Orin市场份额。针对BEV+Transformer:地平线开发适配J5的Swin-Transformer结构,可更好发挥J5的算力优势,显著提升网络性能、减少访存时间。此外,在3D感知算法领域,地平线参考算法集成了基于Transformer的纯视觉BEV模型、基于雷达点云的3D检测模型以及单目3D目标检测算法。地平线所提供的BEV感知模型集成了目标检测和语义分割多重任务,可开放支持包括IPM(InversePerspectiveMapping)、Transformer等多种转换方式,基于Transformer大模型,开放提供包括DETR3D、GKT、PETR在内的多类感知示例。地平线还于2023年上海车展发布最新3.0BPU架构纳什,专为大参数量Transformer、大规模交互式博弈设计,可灵活支持Transformer的细小算子。
黑芝麻:在功能完整性与性价比上具备一定优势,相比于部分ASIC路线公司产品,或更能够适应BEV+Transformer新趋势。黑芝麻主要瞄准中高算力市场,华山系列A1000、A1000Pro、A2000的算力分别为58、106和256TOPS。此前,黑芝麻A1000的量产进程有所延迟,目前有望于今年上车江淮思皓与领克08,正式开启商业化之路。针对BEV+Transformer:黑芝麻自研NPU具有较好兼容性,可兼顾Transformer算法。黑芝麻自研神经网络加速器NPU以及图像信号处理ISP两大核心IP,使得A1000具备高性能&高能效,能够做到卷积层平均80%的MAC阵列利用率,有助于客户在大模型与复杂算法场景下更高效开发。辉羲智能:瞄准BEV+Transformer行业新趋势,切入大算力芯片市场,有望抓住软硬件尚未固化的窗口期,实现弯道超车。公司成立于2022年,创始团队具备微软亚洲研究院、百度、商汤、上汽、蔚来以及上海交大等产学研背景,拥有芯片&自动驾驶系统研发设计,以及量产适配上车的深厚经验积累。公司于2023年2月完成由顺为资本和小米联合领投的数亿元天使+轮融资。当前产品涵盖车端智能驾驶芯片和计算平台、云端数据智能平台、城区NOA和GPT模型应用等全栈式解决方案。芯片层面,公司首款产品R1SoC即针对BEV+Transformer以及舱驾一体新趋势进行设计,规划算力超260TOPS,有望于2024H1SOP,具备支持BEV+Transformer的最新架构。公司主打“数据闭环定义芯片”,基于自研大算力架构,介于ASIC和GPU之间,因此算法灵活性与通用性较高,能够在AI算力、CPU/GPU性能、内存带宽以及整体架构上支持大模型算法以及跨域计算等需求。工具链&生态层面,公司积极构建工具链生态,利于客户加速向国产化平台迁移。辉羲提供完整工具链RhinoRT,做到CUDALike,支持BEV/Transformer算法部署,同时支持常见的AIstack以及客户的自定义算子,有利于加速现有英伟达产品客户的迁移效率。华为:定位Tier1,多维度赋能车企造车,自研MDC计算平台在架构与算力上表现突出。我们认为,基于MDC计算平台、通信技术、大模型积累以及鸿蒙底层生态,华为将持续引领自动驾驶基础软硬件行业,但目前仍主要面向智选车生态合作伙伴,向更广泛车企拓展的能力仍待观察。MDC平台为自动驾驶提供可扩展且灵活的算力支持。华为MDC平台基于多颗鲲鹏CPU与昇腾AI芯片的SoC组合,推出MDC210、MDC300F、MDC610和MDC810,实现48TOPS–400+TOPS的算力,覆盖L2+至L4级别自动驾驶。MDC平台遵循平台化和标准化原则,能够以一套软件架构,支持不同硬件配置,实现软硬件解耦。同时,MDC平台充分考虑到感知、决策、规划、控制等不同环节对CPU和AI算力的不同需求,由自研鲲鹏SoC提供CPU算力,昇腾SoC提供AI算力。2021年4月,华为宣布MDC810已实现量产,并于2022年正式上车北汽极狐阿尔法SHi版以及长安阿维塔11,MDC610也于2022年量产上车。
市场空间:中国自动驾驶芯片市场2030年有望超700亿元
中短期来看,随着价格战打响,不同价位车型的智能化方案或有所分化,进而产生对芯片算力和架构的不同需求。而长期来看,智能化渗透率决定需求,中央计算、大模型等新范式决定技术路线,量产经验、工具链、性价比决定规模与竞争格局。自动驾驶芯片将是全产业链格局最为稳固、集中度最高的环节,我们判断,全球市场4-5家、国内市场3-4家寡头或有望占据行业80%-90%以上的市场份额。同时,我们对国内市场2022-2030E自动驾驶芯片市场规模进行测算,至2025年有望超100亿元,至2030年有望超700亿元。我们测算的核心假设如下:1)乘用车销量:我们假设2023至2030年,中国乘用车销量以年平均1%速度增长。2)功能渗透率:针对传统L1/L2功能,我们预计未来2-3年将是功能快速规模放量的阶段,分别将于2024和2026年达到渗透率的最高点(25%/40%),随后开始逐渐下降,预计至2030年分别约3%和30%。针对NOA功能,我们预计高速NOA将于2023年开始加速落地,而城区NOA今年才正式开始上车,且需要3年左右的时间实现“从有到优”,因此我们假设至2025年高速/城区NOA渗透率将分别达到15%/1%,至2030年渗透率将分别达到45%/20%。而L4距离真正落地仍有较远距离,我们认为Robotaxi大规模铺开的前提是前装量产车型的推出,而目前运行的车型仍为后装改造车。根据我们进行的产业链调研,头部L4玩家皆规划在2025年前后推出前装量产车型,届时才有可能冲击万台规模,因此我们测算至2025/2030年,L4渗透率将分别约0.05%/2.0%,对应车队规模超1万和50万台。3)芯片配置:我们假设,传统L1/L2功能单车配备1/1.5颗小算力自动驾驶芯片,高速NOA功能(L2+)单车配备1颗中算力自动驾驶芯片,城区NOA功能(L2++/L3)单车配备2颗大算力芯片,L4/L5等全无人自动驾驶单车则需要平均配备4颗大算力芯片。4)芯片单价:L1/L2等级自动驾驶系统通常配备以MobileyeEyeQ3、地平线J2/J3为代表的中低算力芯片,以J2约20-30美元、J3约50美元的价格测算,我们假设L1/L2所配备的自动驾驶芯片单颗平均为100/200元。对于配置高速NOA功能的车型,中算力芯片单价参考黑芝麻A1000约100美元、英伟达Xaiver约150美元,我们假设单颗平均价格为1000元。对于配置城区NOA以及L4/L5功能的车型,我们参考英伟达OrinX约400美元的单价测算,假设单车配备的芯片平均单颗为2500元。上述价格皆针对2022年进行假设,而伴随量产规模扩大,我们认为芯片单价将呈逐步递减趋势,且在中低算力芯片上表现更为显著。

微信"扫一扫",分享转发
微信联盟:汽车芯片微信群、SoC微信群、域控制器微信群、汽车电子微信群,各细分行业微信群:点击这里进入。
鸿达安视:水文水利在线监测仪器、智慧农业在线监测仪器 查看各品牌在细分领域的定位宣传语














达成战略合作!")

评论排行