
世界模型新探索,中科院自动化所牵头队伍获得国际比赛第一名
世界模型新探索,自动化所牵头队伍获得国际比赛第一名
机器人要在开放环境中可靠完成操作,不仅需要识别当前场景,更需要理解动作执行后环境如何变化。动作条件世界模型(Action-conditioned World Model)正是面向这一关键能力的重要技术路径:给定初始视觉观测和机器人动作序列,模型需要预测机器人执行过程中的视觉演变,从而为规划、评估和闭环控制提供可预判的环境动态。
近日,在全球机器人领域顶级学术会议ICRA 2026上举办的AGIBOT World Challenge世界模型赛道上,自动化所团队牵头的NeoVerse-ABot队伍以显著优势获得冠军。团队模型在图像质量(Visual Quality)和动作跟随(Action Following)两个指标上均排名第一。这一结果表明,模型不仅能够生成高质量机器人操作视频,更能够稳定响应动作条件,将控制信号准确转化为机器人运动、接触过程和物体状态变化,为世界模型在真实机器人操作中的应用提供了重要验证。
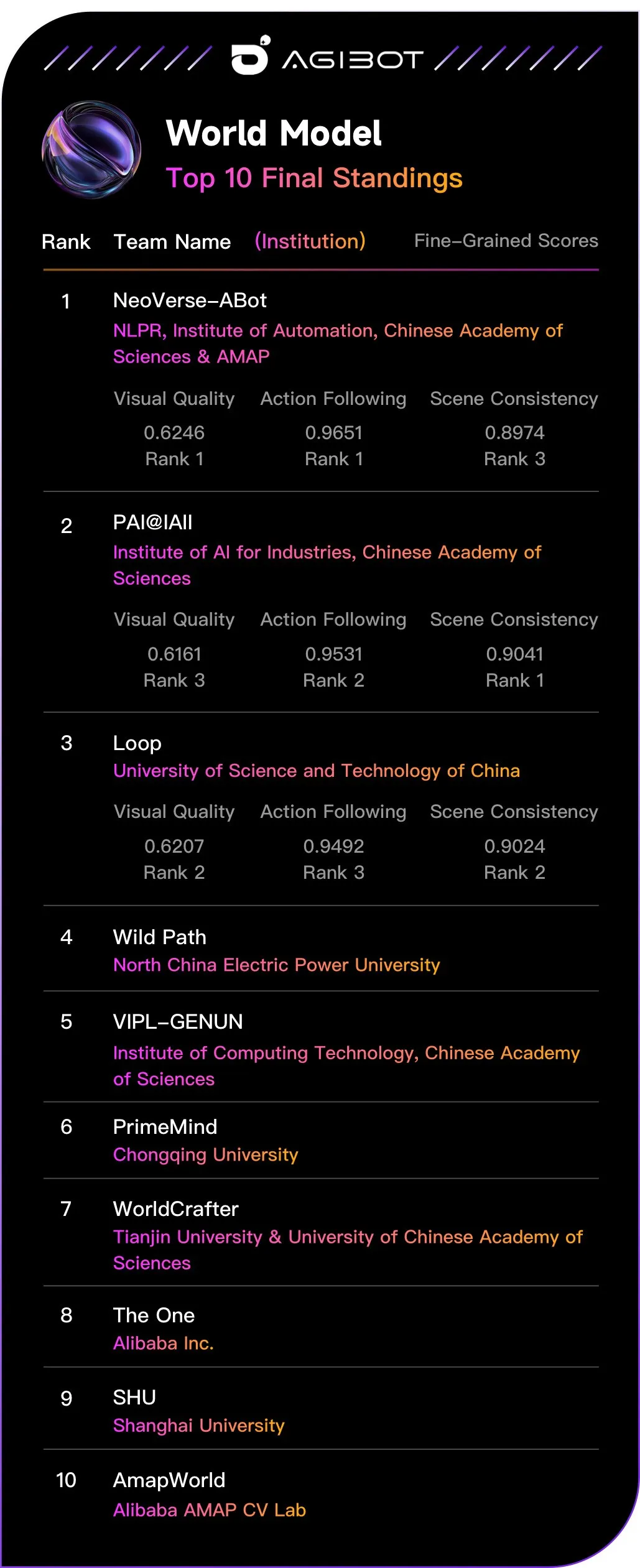
赛事榜单
前瞻布局:构建具身智能的“物理常识库”
在迈向通用人工智能的过程中,如何让机器人像人类一样具备对物理世界的预判能力,是具身智能领域的核心挑战。世界模型作为机器人感知与决策的桥梁,赋予了机器“在大脑中预演”的能力,使其能够提前预判动作带来的物理反馈。
团队敏锐地察觉到,当前的机器人控制往往过度依赖实时感知,缺乏对复杂交互后果的深度理解。为了突破这一瓶颈,他们从底层物理逻辑出发,致力于探索动作条件下的世界模型,旨在为机器人打造一套能够理解因果、预判未来的“物理大脑”。
面向真实机器人操作的世界模型研究探索
本次世界模型挑战赛主要考察模型在给定初始视觉观测和机器人动作序列后,对后续操作过程视觉演变的预测能力。与传统视频生成任务相比,该比赛更强调具身交互理解、动作条件跟随和物理结果模拟,要求模型在分布外场景和失败轨迹中仍然根据动作信号生成合理后果,因此具有较高的技术挑战性。来自全球学术界、工业界的153支顶尖团队展开激烈角逐。
自动化所参赛队伍构建了一种基于扩散模型的高保真动作条件视频生成框架NeoVerse-ABot,通过创新的时序对齐算法与多维度条件增强机制,实现了复杂操作任务下物理演变过程的精准模拟,其核心优势体现为:
1.长时上下文建模,保持状态连续性
团队围绕机器人操作场景系统优化长时序上下文建模能力,使模型能够覆盖更完整的操作过程,而不是只依赖短片段局部关联。在机器人任务中,许多物理结果并非瞬时发生,而是由动作执行、接触建立、物体响应和状态变化逐步累积形成。更长范围的时序建模能力,使模型在推演过程中能够保持稳定的状态连续性和物理一致性,减少长时预测中的状态漂移。
2. 细粒度动作校准,实现精准条件控制
在条件构建和推理阶段,团队进行了细粒度几何校准,使动作条件与生成视频在空间几何和视角关系上保持高度一致。相比仅让视频“看起来像在执行动作”,该模型更强调对给定控制信号的精准跟随,能够更准确地反映动作与物体状态之间的因果关系。这种对齐能力在空抓、掉落、接触失败和轨迹偏移等非理想场景中尤其关键。
3. 优化数据与训练机制,抑制动作幻觉
为提升模型在真实机器人场景下的泛化能力,团队对训练数据中的任务类型、动作阶段、物体交互状态以及成功与失败轨迹进行系统整理和配比优化,显式保留真实操作中的长尾与边界样本。此举使模型能够学习更完整的操作结果分布,降低生成“默认成功”结果的倾向。
团队还引入基于强化学习的反馈机制,围绕动作跟随和物理合理性强化模型对控制输入的敏感性,从而更准确地区分成功接触与失败操作,缓解机器人视频生成中常见的动作幻觉问题。在未成功接触、物体状态偏移等情况下,模型能够根据动作信号和环境状态生成更符合物理直觉的后续变化,而不是简单生成理想化成功结果。
此外,所提出世界模型对在同一场景中编辑的多种不同动作也具有高度服从性和物理一致性。
推动世界模型研究迈入开放场景,开启新篇章
NeoVerse-ABot在国际比赛中的卓越表现,验证了动作条件世界模型在处理复杂具身交互任务中的巨大潜力。展望未来,团队将进一步探索世界模型与大规模强化学习、在线规划算法的深度融合。
一方面,团队计划将该模型作为“神经仿真器”,为机器人策略训练提供海量且具备物理真实性的合成数据,解决真机数据获取成本高、长尾场景覆盖难的问题;另一方面,研究将聚焦于提高模型的实时推理速度,使其能够直接嵌入到机器人的闭环控制中,实现边思考、边预判、边执行。
随着研究的深入,这种具备强泛化能力的世界模型将不仅局限于实验室环境,更将助力机器人在非结构化的开放场景中,实现更加安全、灵活且智能的自主操作,开启具身智能从“视觉识别”向“物理理解”跨越的新篇章。
我要收藏
点个赞吧
转发分享

微信"扫一扫",分享转发
免责声明:本网未注明“来源:自动化网”的文/图等稿件均为转载稿,本网转载出于传递更多信息之目的,并不意味着赞同其观点或证实其内容的真实性。 如本网转载内容涉及版权问题以及对文章内容有疑议,请发邮件至edit@zidonghua.com.cn,我们将及时处理。
微信联盟:机器人微信群、具身智能微信群,各细分行业微信群:点击这里进入。
鸿达安视:水文水利在线监测仪器、智慧农业在线监测仪器 查看各品牌在细分领域的定位宣传语



微信联盟:机器人微信群、具身智能微信群,各细分行业微信群:点击这里进入。
鸿达安视:水文水利在线监测仪器、智慧农业在线监测仪器 查看各品牌在细分领域的定位宣传语






评论排行